Your Users Ask One Question, Your Retriever Searches Another
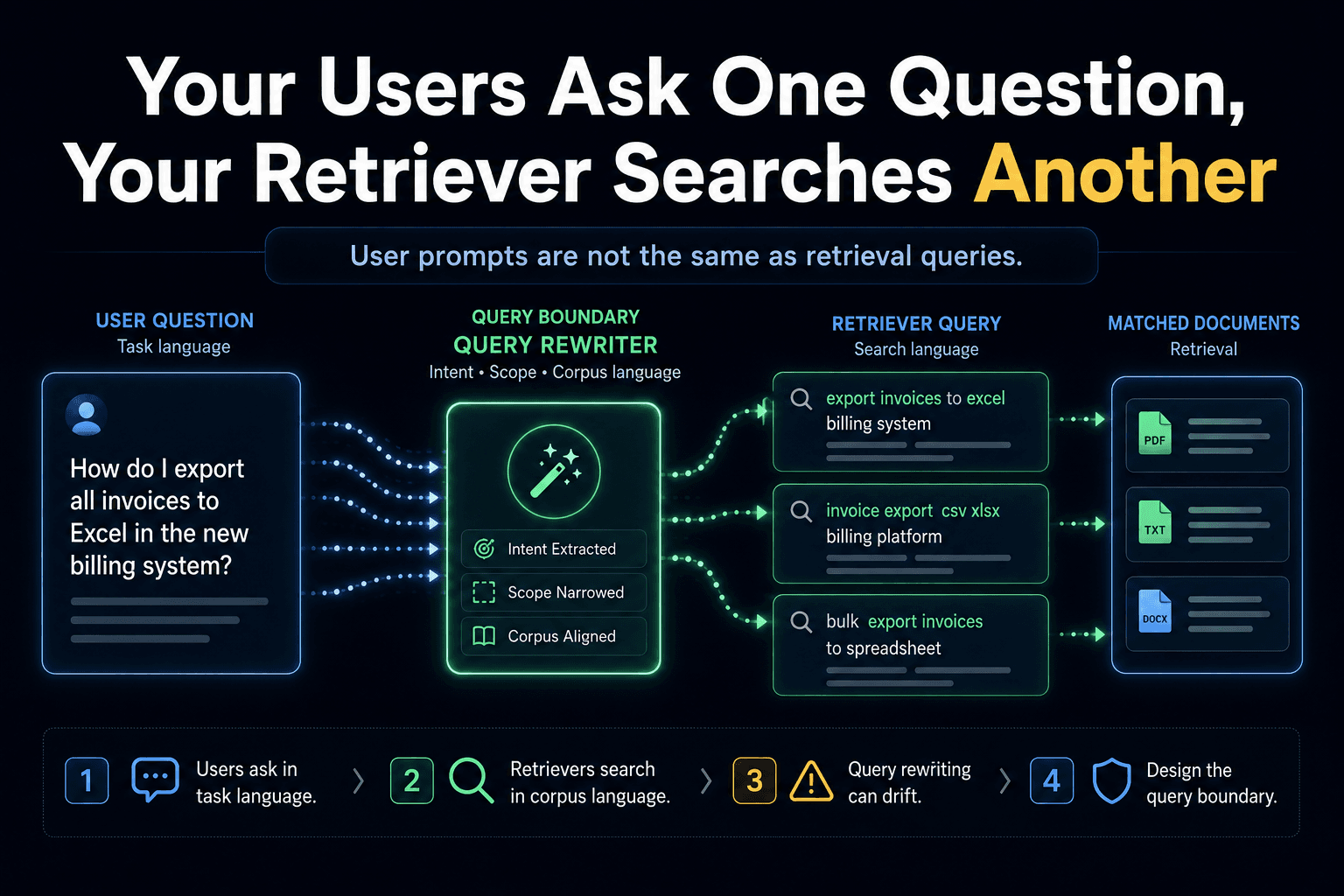
A user types a question into your RAG system. Before anything is retrieved, a decision gets made: what string do we actually search with? In a lot of systems, nobody made that decision on purpose. The raw prompt goes straight to the retriever, and whether that works is left to luck.
Sometimes it works. Often it doesn't — and when it doesn't, the symptom is maddening, because the system clearly "understood" the question and still retrieved the wrong things.
The thing everyone tries first
The mainstream fix is query rewriting: have an LLM expand, rephrase, or multi-query the user's question into better search strings. This is now standard, and it genuinely helps with vocabulary gaps — the user says "login broken," the docs say "authentication failure," and a rewrite bridges them.
But query rewriting is usually framed as a trick to generate alternate search strings. That framing is what gets people stuck, because it treats the mismatch as a phrasiふng problem to paper over, rather than a boundary problem to design.
Why rewriting alone doesn't settle it
Here's the trap: a rewrite that improves retrieval can also quietly change the question. The user asked one thing; the rewritten query retrieves great documents for a slightly different thing; the answer is fluent, well-grounded, and not actually what they asked. You improved recall and lost fidelity, and nothing in the system noticed, because retrieval metrics went up.
The deeper issue is that there are really two languages in the room — the user's task language and the corpus's author language — and the retriever sits on the boundary between them. Synonyms, acronyms, internal terms, and the same word meaning different things in query and document all live on that boundary. Treating it as "just rewrite the query" hides the fact that you're making a translation decision with consequences.
The one design shift
Treat the gap between user question and search query as an explicit interface boundary, not a hidden preprocessing step. Decide, on purpose: what does the retriever actually search for, how is the user's language reconciled with the document's language, and — critically — does the rewritten query still answer the question that was asked?
The move is to make that translation visible and checkable, so that "we rewrote the query" doesn't silently become "we answered a different question." When the user's intent can't be safely mapped to the corpus, that's information — sometimes the honest output is that the system can't answer this question from this corpus.
Where this comes from
In the setting I work in — high-security, high-complexity, often without a frontier model to lean on — you can't trust a large model to silently "figure out" the user's intent. The boundary between what the user asked and what the system searched has to be explicit, because a smaller model will confidently retrieve for the rewritten query and never flag that it drifted. Designing the query boundary is how you keep the system answering the question that was actually asked.
If this is where your RAG is stuck
The query boundary is one of three places production RAG dies — the others being the evidence boundary (relevant vs sufficient) and the output boundary (where the answer must stop).
This article describes the failure pattern. The RAG Failure Diagnosis Kit turns these three boundaries into review questions you can apply to your own system — plus a failure-mode map and constrained-model checks for teams debugging production RAG under real constraints.
Get the RAG Failure Diagnosis Kit
If your system retrieves well but answers a subtly different question than the one asked, start at the query boundary.