
Your RAG Retrieved Documents, Not Evidence
Your retriever returned five documents. They're all about the right topic. Your similarity scores look healthy. And the answer your system produced is still wrong.
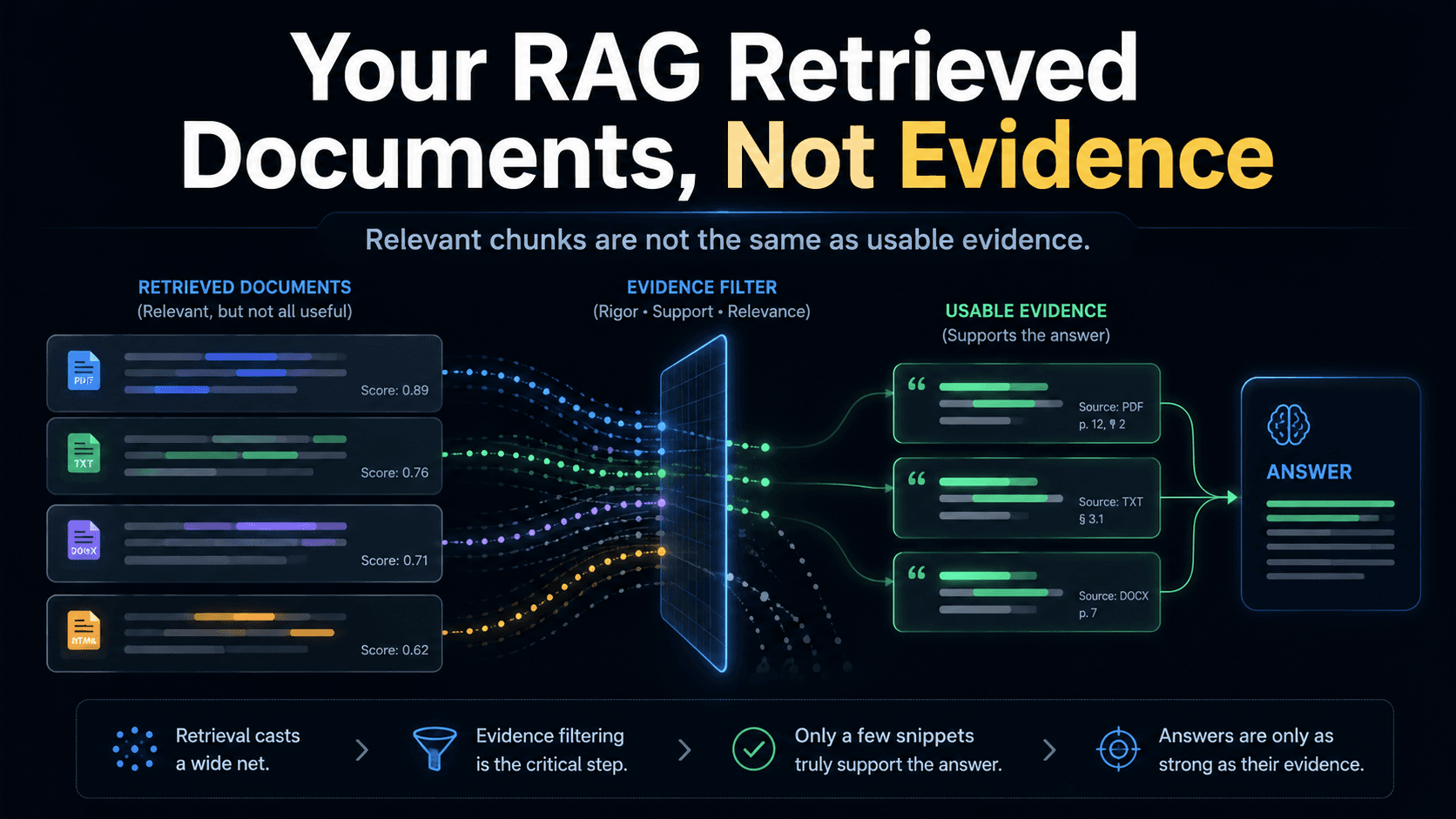
This is the failure that survives every retrieval upgrade. You add a reranker, the documents get more relevant, and the answer is still wrong. You increase top-k, you get more on-topic chunks, and the answer is still wrong. Because the problem was never that the documents were off-topic. The problem is that relevant documents are not the same thing as usable evidence, and most RAG systems never enforce the difference.
The thing everyone tries first
When the answer is wrong but the retrieval "looks fine," the standard moves are: tune chunk size, add hybrid search, add a reranker, raise top-k, swap the embedding model. All of these operate on the same axis — get documents that are more similar to the query. And they can genuinely help when the real problem is that the right document wasn't being retrieved at all.
But they do nothing for the case where the right document was retrieved and the answer is still wrong. In that case you don't have a retrieval problem. You have an evidence problem, and similarity can't see it.
Why "more relevant" doesn't fix it
Similarity answers one question: is this chunk about the same topic as the query? It does not answer the question that actually matters: does this chunk contain the facts needed to support the answer?
Those come apart constantly. A chunk can be highly similar to the question — same vocabulary, same subject — and contain no statement that actually grounds the answer. The model, handed a pile of on-topic text and asked to produce an answer, will produce one. It will sound grounded. It will even sound cited. But the grounding is cosmetic: the text was nearby, not load-bearing.
High similarity with a wrong answer isn't a contradiction. It's the predictable result of optimizing for the wrong target. You asked retrieval to find related text. It found related text. Nobody asked whether the related text was enough.
The one design shift
Stop treating retrieval output as evidence. Treat it as candidate material that has to pass an explicit evidence check before it's allowed to support an answer.
The shift is to make "sufficient evidence" a state your system can be in or out of — not an assumption baked into the fact that retrieval returned something. Concretely, that means a step between retrieval and generation that asks: does the retrieved set actually contain the facts this answer requires? If not, what's missing, and is the correct move to abstain? When the documents don't contain the facts, the system should be able to return nothing rather than a fluent guess.
That single boundary — relevant context in, but only sufficient evidence allowed through to the answer — is what separates a RAG demo from a RAG system someone can trust in production.
Where this comes from
I build LLM/RAG/Agent systems in a high-security, high-complexity setting, where I often can't reach for a frontier model and have to design so the system holds with a smaller or on-prem one. When you can't lean on a large model's slack to paper over weak evidence, this boundary stops being optional. A small model handed insufficient-but-relevant context will confabulate confidently. The only thing that saves you is enforcing the evidence boundary in the system, not hoping the model is smart enough to notice.
That constraint is why I draw the line where I do: surfacing related documents and supplying evidence an expert would accept are different jobs, and production is where blurring them gets expensive.
If this is where your RAG is stuck
This is one of three boundaries where production RAG usually dies — the evidence boundary. The other two are the query boundary (what you actually retrieve for) and the output boundary (where the answer must stop). The hard part is that this failure doesn't show up in your retrieval metrics: recall, precision, and similarity all look fine while the answer quietly misses.
This article describes the failure pattern. The RAG Failure Diagnosis Kit turns these three boundaries into review questions you can apply to your own system — plus a failure-mode map and constrained-model checks for teams debugging production RAG under real constraints.
Get the RAG Failure Diagnosis Kit
If your retriever keeps finding the right documents and your answers keep missing, the evidence boundary is the first place to look.