Your RAG Should Return Evidence, Not Recommendations

You built a system to surface information so a person could decide. Somewhere along the way, it started deciding for them. The output stopped saying "here's what the documents show" and started saying "you should do X." Nobody designed that drift. It happened because an LLM, asked a question, will always produce an answer-shaped thing — and an answer easily becomes a verdict.
The thing everyone tries first
The usual fix is a prompt instruction: "Don't make recommendations." "Only state what's in the documents." "Don't give advice." People add these lines and assume the boundary is now enforced.
It isn't. A prompt instruction is a request, not a guardrail. The model will follow it most of the time and then, on the input that matters, produce a confident recommendation anyway — because nothing in the system structurally prevents it. "Please don't make recommendations" is to a guardrail what a sticky note saying "please don't enter" is to a locked door.
Why this matters more than it looks
When output drifts from evidence into verdict, you've quietly moved the locus of accountability. As long as the system returns evidence and a human decides, the human owns the decision. The moment the system returns a verdict and the human defers to it, the system is making decisions it was never validated to make — and when one is wrong, the accountability is a blank.
This is exactly the line that high-stakes fields draw on purpose. Legal and clinical practice separate evidence extraction from downstream judgment deliberately, because the validation and the responsibility for those two acts are different. Most RAG systems erase that line by default, simply because the model is happy to do both in one breath.
The one design shift
Decide what the output is, and enforce it structurally. An output should declare itself: answer, evidence, missing facts, or out-of-scope. "Return decision material, not a decision" has to live in the system — in the output contract, in gates that check what kind of thing is being returned — not in a polite request to the model.
The stance, said plainly: the system supplies frames, the human supplies verdicts. That's not a limitation to apologize for. In any setting where being wrong is expensive, it's the entire point — the system's job is to make a person able to decide well, not to decide for them and hope.
Where this comes from
I work where decisions carry real consequences and where I frequently can't use a frontier model — so I can't rely on a large model's caution to hold the line. A smaller or constrained model will slide from evidence into verdict even more readily. The only thing that holds is making the output boundary part of the system's structure. That's a design stance I've had to make explicit, because the model won't hold it for you.
If this is where your RAG is stuck
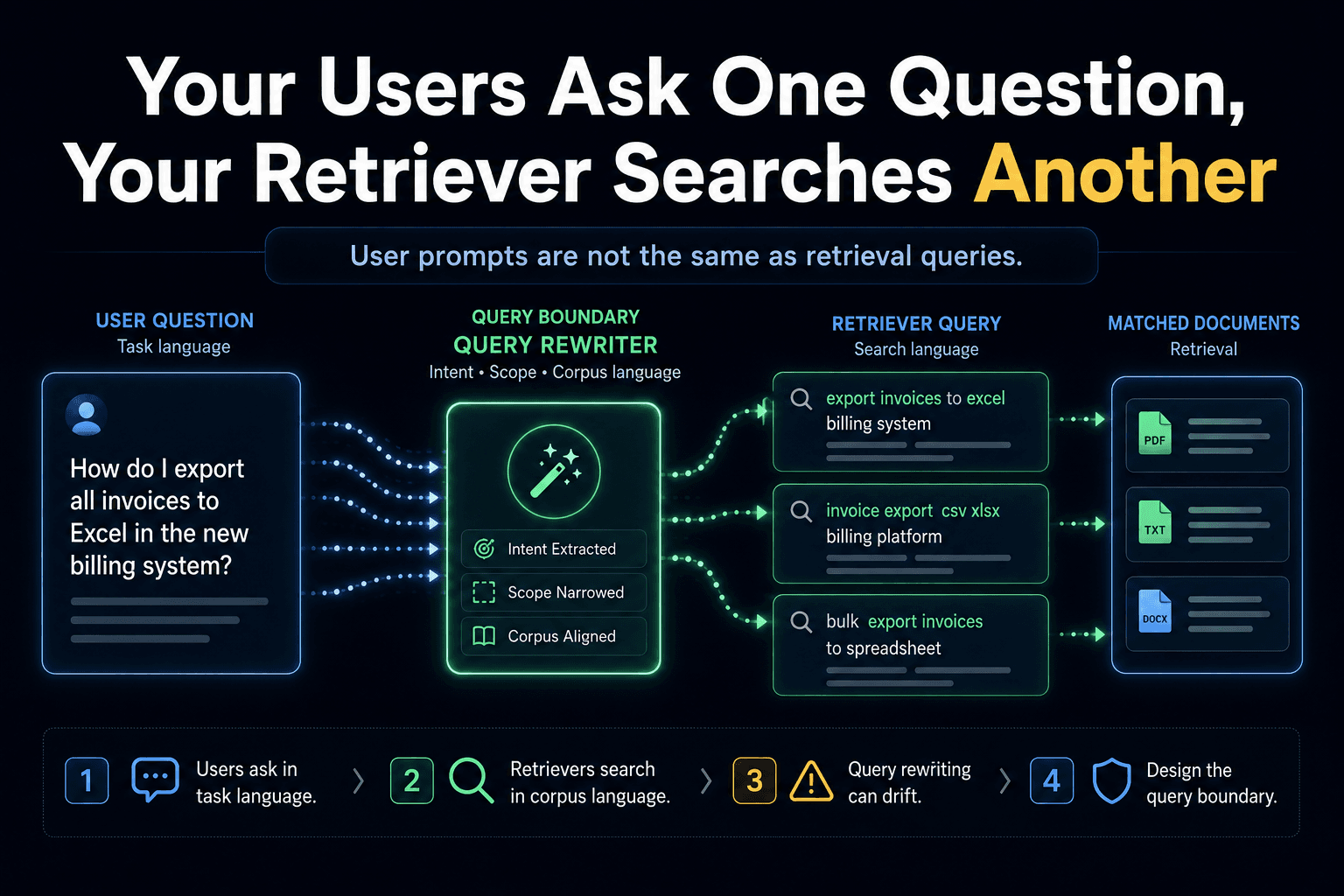
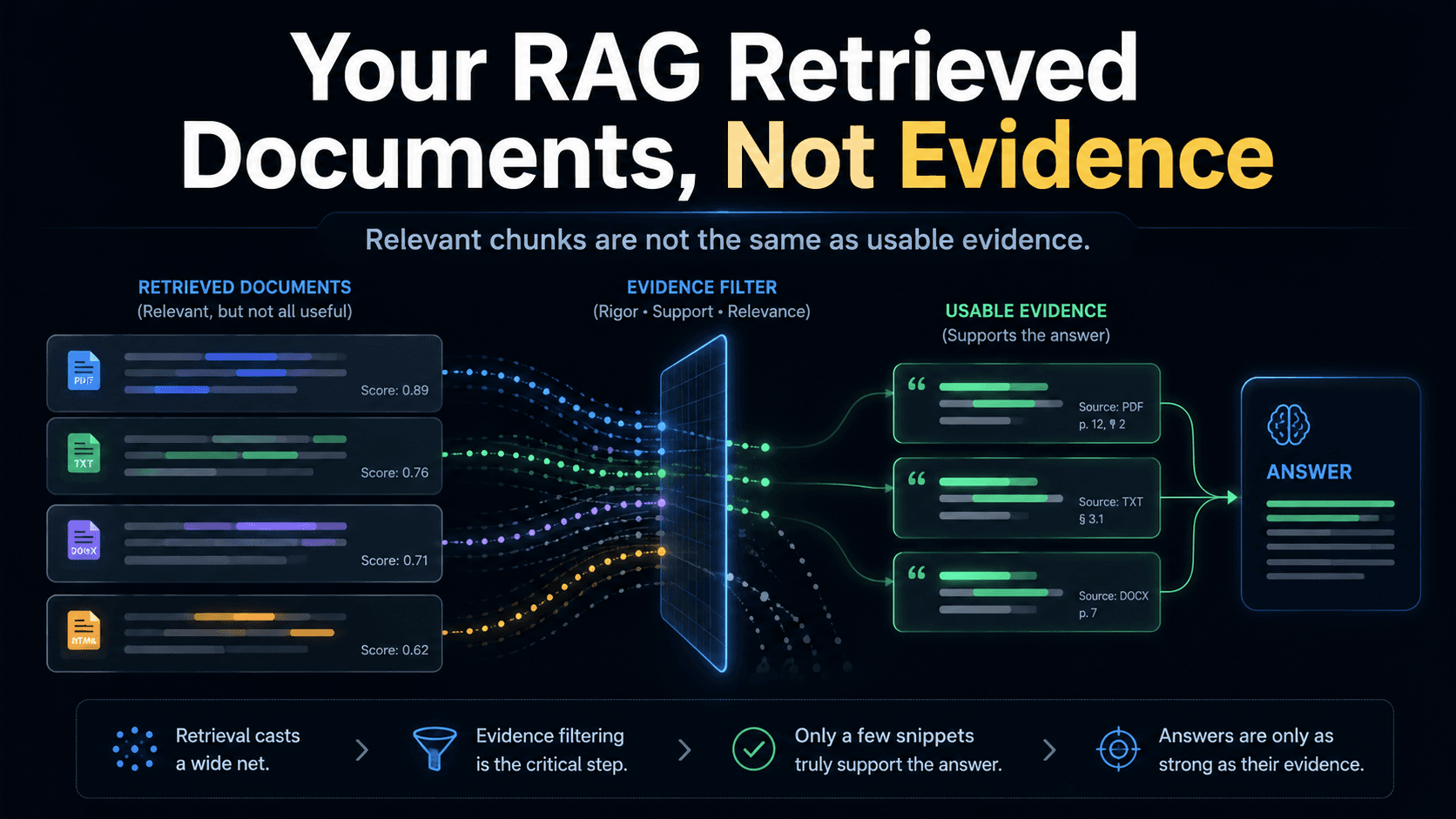
The output boundary is one of three places production RAG dies — alongside the query boundary (what you retrieve for) and the evidence boundary (relevant vs sufficient).
This article describes the failure pattern. The RAG Failure Diagnosis Kit turns these three boundaries into review questions you can apply to your own system — plus a failure-mode map and constrained-model checks for teams debugging production RAG under real constraints.
Get the RAG Failure Diagnosis Kit
If your system has started handing people verdicts instead of evidence, the output boundary is where to start.