RAG Needs a Question Boundary Before It Needs More Context.
When a RAG system fails, the first instinct is usually to inspect the retrieved results.
Were the chunks too small?
Was the embedding model weak?
Should we add a reranker?
Should we retrieve more documents?
Those questions matter.
But in my implementation, the first failure happened earlier.
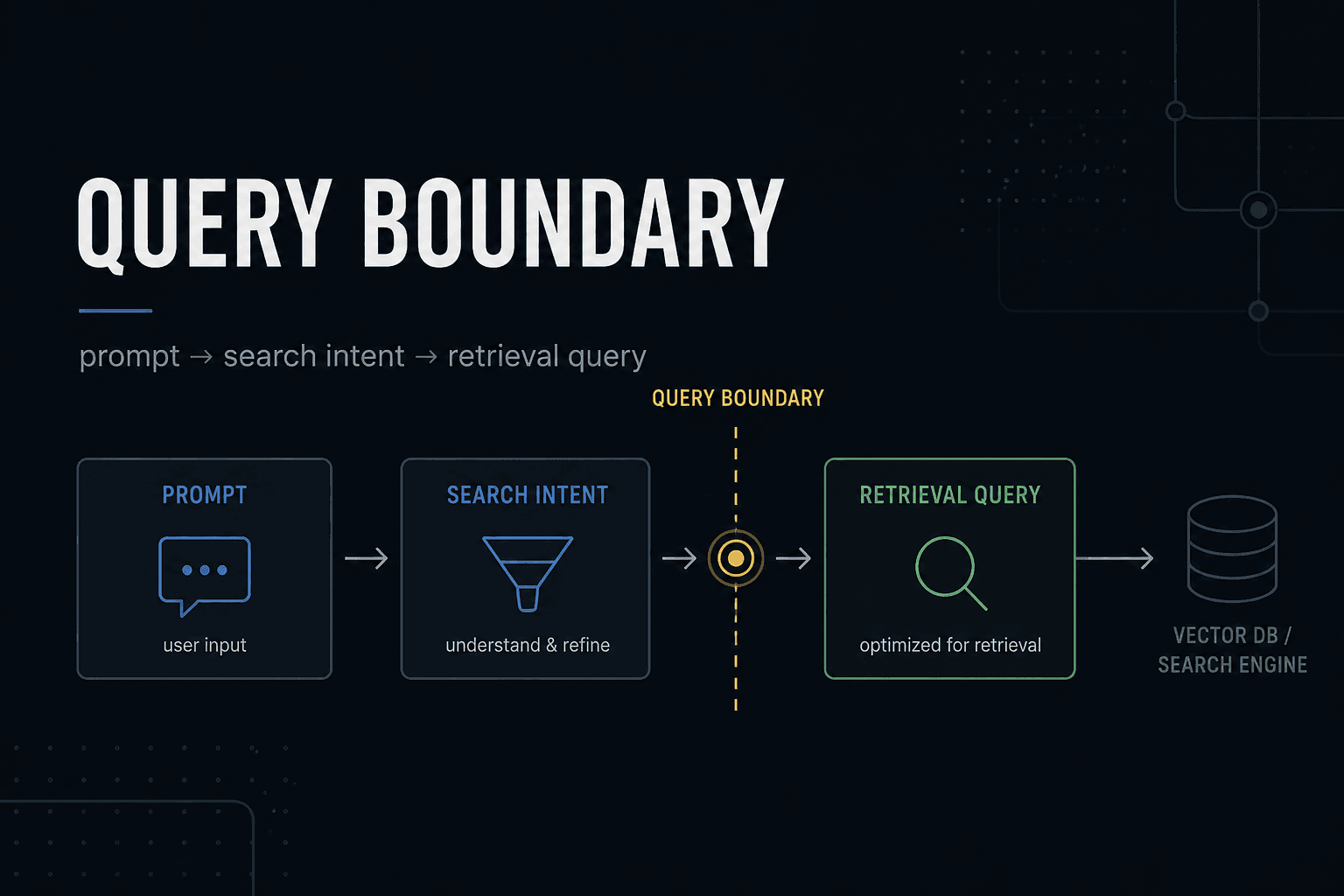
Before the system could retrieve the right evidence, it had not decided what should be searched for.
The user prompt was not the retrieval query.
The extracted rule was not the visual search query.
The missing piece was a query boundary.
This essay is not about optimizing a vector database. It is about a smaller architectural problem that shows up before retrieval: how a runtime turns user intent into something a retrieval system can actually use.
The obvious place to look is retrieval
A common RAG debugging loop looks like this:
bad answer
→ inspect retrieved documents
→ add more chunks
→ tune embeddings
→ add reranking
→ retrieve more context
This is a reasonable loop.
If the retrieved evidence is irrelevant, the answer will drift. If the chunks are poorly shaped, the model will miss the useful parts. If the embedding model is weak, semantic search may pull the wrong neighborhood.
But this loop assumes that the query itself was already the right thing to ask.
That assumption is easy to miss.
I missed it too.
I was building a small project called trend-to-rule. The goal was not to build a fashion assistant. The fashion domain was just a stress test: can a runtime read trend articles, extract reusable rules, and render those rules back into something a person can actually use?
At first, the pipeline felt straightforward.
trend articles
→ evidence
→ common rule
→ suggestion
→ examples
Then I tried to connect the extracted rule back to real visual examples.
That is where the system started to feel off.
The rule made sense as prose. It did not work as a search query.
A user prompt is not a retrieval query
A user naturally describes the answer they want.
For example:
I want an outfit that feels current, but does not look too loud.
That is a good user prompt.
It is not necessarily a good retrieval query.
The prompt describes the desired outcome. Retrieval needs evidence that can help the system reason toward that outcome.
Those are different jobs.
The user may say:
current but not too loud
But the retrieval system may need something closer to:
2026 minimalist outfits relaxed silhouettes neutral colors fashion trend
Or, depending on the workflow:
mens relaxed navy shirt gray wide trousers minimal street style
The difference is not just wording.
It is a boundary between user intent and retrieval intent.
When those two are collapsed into one string, RAG starts to drift before retrieval even begins.
More context does not fix a system that never preserved the right question.
A common rule is not a visual search query
The same problem appeared again later in the pipeline.
The runtime could extract a rule like this:
Use a calm base color and add a slightly relaxed silhouette to make the outfit feel current without leaving familiar territory.
As a rule, this is useful.
It gives the reader a judgment frame.
But if the next step is image search, that rule is still too abstract.
A search engine does not know what to do with:
calm base color
slightly relaxed silhouette
current without leaving familiar territory
A person can understand it. A visual search system needs visual handles.
So the runtime needs another transformation:
common rule
→ visual search intent
→ image search query
For example:
navy relaxed shirt gray wide trousers minimal outfit
or:
women beige oversized blazer straight jeans minimal street style
This is not image generation.
The goal is not to invent a synthetic outfit. The goal is to connect an extracted rule to real examples that help the user see what the rule means.
The rule is for judgment.
The query is for retrieval.
Treating them as the same artifact is where the system quietly loses contact with reality.
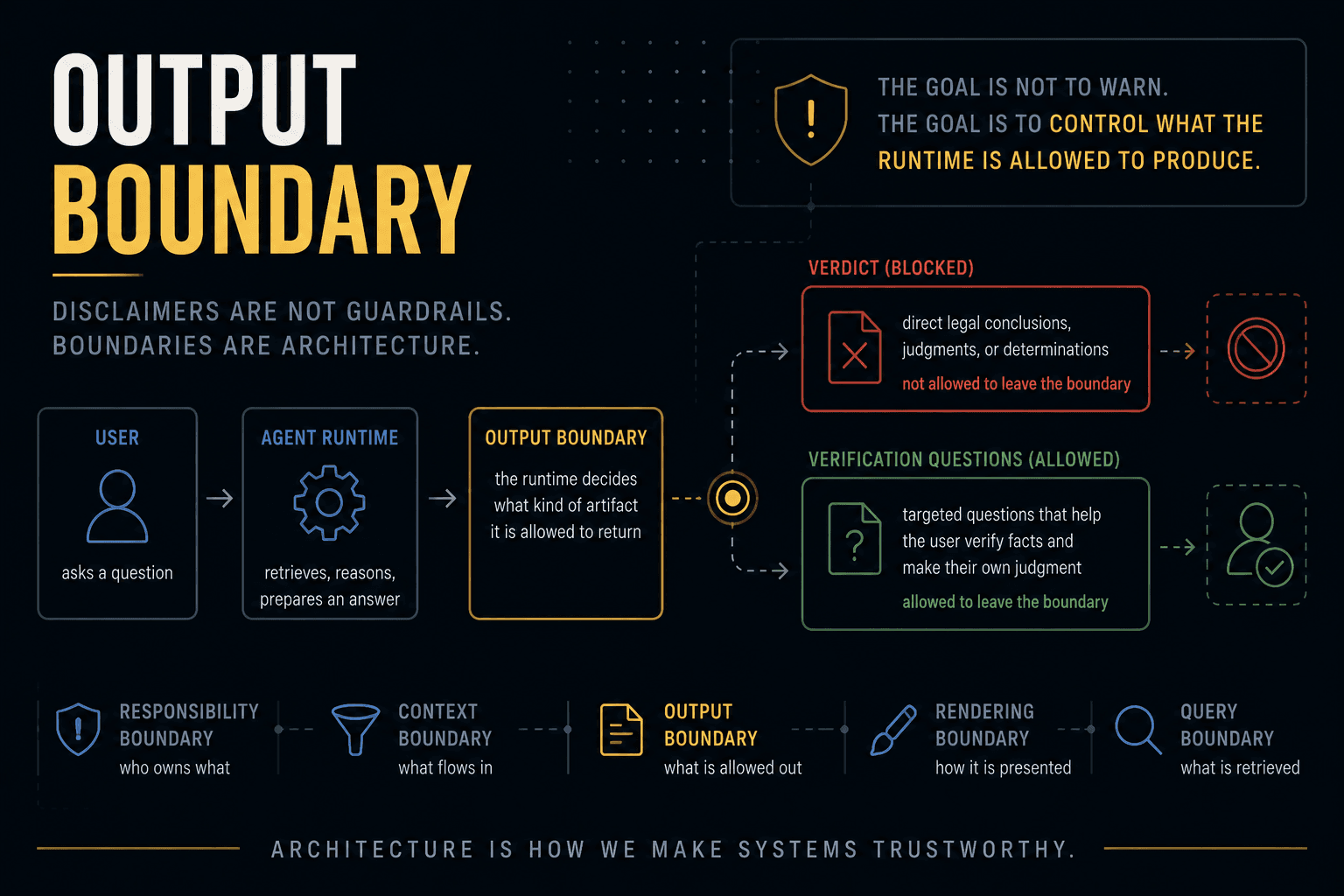
The runtime needs a transformation boundary
The important part is not that the query became longer or more specific.
The important part is that the transformation became explicit.
user prompt
→ search intent
→ retrieval query
common rule
→ visual search intent
→ image search query
Each arrow is a runtime responsibility.
If the system hides this transformation inside one prompt, it becomes hard to inspect.
If the final answer is wrong, where did the failure happen?
Did the user ask an ambiguous question?
Did the runtime preserve the wrong intent?
Did retrieval fetch weak evidence?
Did the model summarize instead of structure?
Did the final rendering hide the useful distinction?
Without a boundary, all of those failures collapse into one vague complaint:
RAG did not work.
That is not enough to debug a system.
Retrieval is not the start of RAG
RAG is often described as if retrieval is the first real step.
But in practice, retrieval depends on a prior decision:
What should this system search for?
That question should not be left entirely to the final prompt.
It belongs in the runtime.
A runtime can decide:
What part of the user request is intent?
What part should become a retrieval query?
What evidence is needed?
What artifact should be returned from retrieval?
What should remain visible for later inspection?
This is why I think RAG needs a question boundary before it needs more context.
The boundary does not make retrieval smarter by itself.
It makes the responsibility inspectable.
The real failure was not search quality
In the trend-to-rule experiment, the first version felt like a normal RAG problem.
The results were not good enough, so it was tempting to blame retrieval.
But the more useful diagnosis was different:
The system had extracted a usable rule.
But it had not transformed that rule into a usable search intent.
That is a different kind of bug.
It is not solved by adding more chunks.
It is not solved by asking the model to “be more specific.”
It is not solved by dumping more context into the final answer.
The missing piece is a runtime step that turns one artifact into another.
rule for judgment
→ query for search
→ examples for grounding
Again, boundary appears.
Perfect. Painful. Predictable.
This is why RAG should not dissolve everything into prose
A weak RAG pipeline often turns everything into one smooth answer.
The user asks a question.
The system retrieves some documents.
The model writes a response.
The answer sounds reasonable.
But the intermediate responsibilities disappear.
What was the search intent?
What evidence was used?
What claim was extracted?
What conflict was found?
What rule was formed?
What query was used to ground that rule back into examples?
If all of that disappears into prose, the system may feel elegant while becoming harder to trust.
Readable output is good.
But readability should not require destroying the structure that made the answer inspectable.
The runtime should preserve the structure.
The final answer should render it.
Those are different responsibilities.
Implementation reference
This essay is based on an implementation experiment in:
- GitHub:
https://github.com/mofuteq/trend-to-rule
The project explores how trend articles can be transformed into structured judgment materials: claims, conflicts, gaps, common rules, suggestions, and rendered explanations.
The code is not the point of this essay, but it is where the boundary became visible.
Support
I write these notes as part of an ongoing implementation log around LLM agent runtimes and RAG systems.
If you find them useful, you can support the work here:
Related essays
This article continues the same boundary-oriented thread:
Structure Belongs to the Runtime. Expression Belongs to the User.MCP Did Not Need More Tool Autonomy. It Needed a Context Boundary.
Closing
When RAG fails, it is natural to inspect the retrieved documents.
But sometimes retrieval is not the first failure.
Sometimes the system never decided what question should become searchable.
The prompt describes what the user wants.
The query describes what the system needs to retrieve.
Treating them as the same thing is where many RAG systems start to drift.
RAG does not start at retrieval.
It starts at deciding what the question becomes inside the runtime.